从输入的手机号码通话记录中找出聊天达人(通话次数最多的人)...
一、设计思路
对本题目进行分析,需要从随机生成的大量手机用户通话记录中找出其中通话次数最多的聊天达人,可以知道本次作业主要是实现一个简单的排序程序,从输入的手机号码通话记录中找出聊天达人(通话次数最多的人)。
上述代码分为四部分,首先是使用随机数生成电话号码字符串,同时定义一个字典,用来存放输入的手机号码通话记录,然后对字典中的数据进行统计求和,最后将字典转换为列表。
接下来进行排序,本次作业实现了冒泡排序和快速排序两种排序方式,这里是按照通话次数从大到小排序。
然后实现find_max函数,用来找出聊天达人,即通话次数最多的人。
最后,在本次实验中我调用的是交换排序中的冒泡排序和快速排序,并调用find_max函数,输出最终的聊天达人信息。
二、设计过程(使用的数据结构、涉及到的算法和知识点)
该代码中主要使用了字典及列表结构;
该代码中使用了快速排序和冒泡排序算法;
(1)字典:字典是另一种可变容器模型,且可存储任意类型对象,字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号,分割,整个字典包括在花括号 {} 中 。
(2)列表:列表是 Python 中使用最频繁的数据类型,它可以作为一个方括号内的逗号分隔值出现。
(3)交换排序:内排序中的交换排序,基本思想就是两两比较待排序元素的关键字,发现这两个元素的次序相反时即进行交换,直到没有反序的元素为止。
①快速排序:快速排序是一种分治算法,可以将一个数组或者列表快速排序,它的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分关键字小,则可以分别对这两部分记录继续进行排序,以达到整个序列有序。
②冒泡排序:冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
三、算法代码
def quick_sort(data):
"""快速排序"""
if len(data) >= 2:
mid = data[len(data) // 2]
left, right = [], []
data.remove(mid)
for num in data:
if num[1] >= mid[1]:
right.append(num)
else:
left.append(num)
return quick_sort(left) + [mid] + quick_sort(right)
else:
return data
def bubble_sort(num_list):
"""冒泡排序"""
length = len(num_list)
for i in range(length):
for j in range(1, length - i):
if num_list[j - 1][1] > num_list[j][1]:
num_list[j], num_list[j - 1] = num_list[j - 1], num_list[j]
return num_list
def find_max(lis):
max_num=0
max_phone_num=[]
for i in lis:
if i[1]>max_num:
max_num=i[1]
for i in lis:
if i[1]==max_num:
max_phone_num.append(i[0])
return len(max_phone_num),max_phone_num,max_num
if __name__ == '__main__':
sum={}
n=input('请输入通话记录条数:')
for i in range(int(n)):
record=input('请输入通话记录').split()
sum[record[0]] = sum.get(record[0], 0) + 1
sum[record[1]] = sum.get(record[1], 0) + 1
dictlist = []
for keys, value in sum.items():
temp = (keys, value)
dictlist.append(temp)
#冒泡排序
bubble_res=bubble_sort(dictlist)
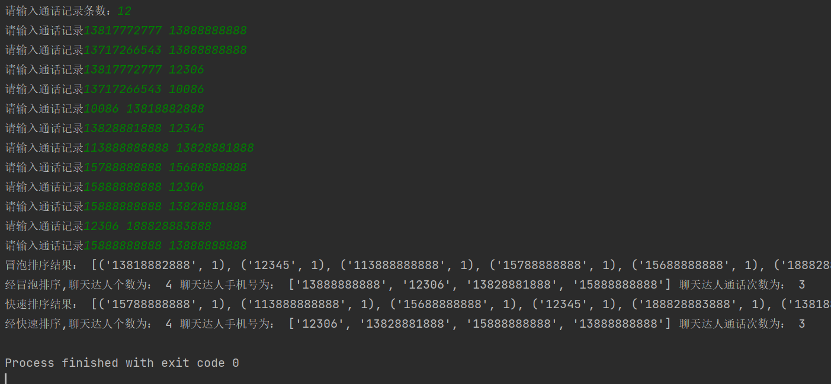
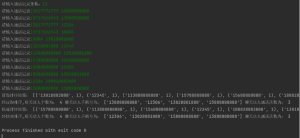
print('冒泡排序结果:',bubble_res)
winner_num,winner_lis,max_num=find_max(bubble_res)
print('经冒泡排序,聊天达人个数为:',winner_num,'聊天达人手机号为:',winner_lis,'聊天达人通话次数为:',max_num)
#快速排序
quick_res=quick_sort(dictlist)
print('快速排序结果:',quick_res)
winner_num, winner_lis, max_num = find_max(quick_res)
print('经快速排序,聊天达人个数为:', winner_num, '聊天达人手机号为:', winner_lis, '聊天达人通话次数为:', max_num)
四、运行截图
五、时间复杂度
快速排序:O(nlogn)
冒泡排序:O(n)
六、总结
1、优点:
(1)该段代码实现了一个基于python的简单通话记录查询程序,能够查询出每个用户的通话次数,进行排序,获取最多通话次数的用户及该用户的通话次数。
(2)支持两种排序方式,冒泡排序和快速排序,能够满足不同的排序需求。
2、不足:
(1)代码中有重复的计算,可以通过提取函数和添加缓存来提高效率。
3、解决的问题:
(1)该代码主要解决了一个简单的通讯记录查询问题,能够查询出每个用户的通话次数,进行排序,获取最多通话次数的用户及该用户的通话次数。
4、开发时可能遇到的困难:
(1)如何准确的获取用户的通话次数:这个可以通过字典的方式来记录每个用户的通话次数,每次记录都将用户的通话次数加一。
(2)如何实现排序:可以使用快速排序和冒泡排序实现排序,获取通话最多的用户。





 上一篇
上一篇 
