当今年轻人希望自己有一段完美幸福的婚姻,但是有些人或受到他人恐吓,或看到一些影视剧及新闻报道,开始担忧自己未来的婚姻幸福问题,甚至产生了恐婚现象。那么就派生出一个问题,婚姻幸福到底与那些因素有关?我选取了三个方面(个人理念,客观因素,现实状况)他们分别为:“对个中国有关性方面的态度”,“个人出生日期”“家庭年总收入”进行研究,进而分析三个大方面对婚姻幸福感的影响。
#提取数据
import os
import pandas as pd
path1 = "D:\\996"
path2 = "./data"
if not os.path.exists(path2):
os.mkdir(path2)
for filename in os.listdir(path1):
if filename.endswith(".csv"):
file_path1 = path1 + "/" + filename
df1 = pd.read_csv(file_path1,encoding='gbk',low_memory=False)
df2 = df1[['a38','a39', 'a40', 'a41','a421','a422','a423',
'a424', 'a425', 'a62','a69','a301']]
df2.to_csv(path2 + "/" + filename,
index=False, encoding="gb2312")
print("完成!")
#第一次数据
import pandas as pd
import numpy as np
import csv
data = pd.DataFrame()
data =pd.DataFrame(pd.read_csv('D:\\996\\grtd.csv',encoding="gbk"))
y = np.array(data['a69'])
x1 = np.array(data['H66'])
x2 = np.array(data['a62'])
x3 = np.array(data['a301'])
import scipy.stats as stats
r1 = stats.pearsonr(x1,y)[0]
r2 = stats.pearsonr(x2,y)[0]
r3 = stats.pearsonr(x3,y)[0]
import pandas.tseries
import statsmodels.api as sm
import pandas as pd
import numpy as np
vars = ['a69','H66','a62','a301']
df = data[vars]
from patsy import dmatrices
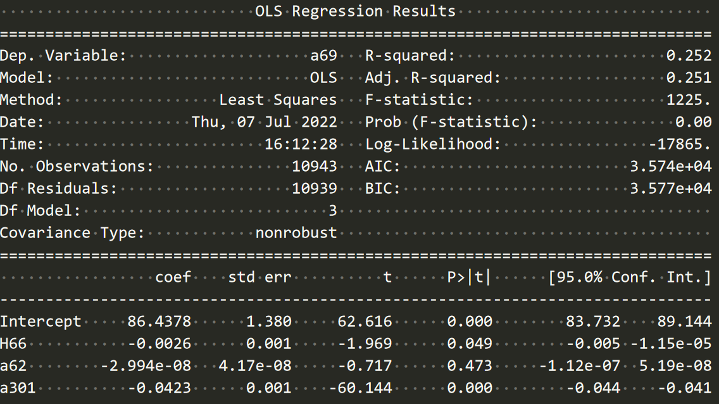
y,X = dmatrices('a69~H66+a62+a301',data = df,
return_type = 'dataframe')
model = sm.OLS(y,X)
result = model.fit()
print(result.summary())
#第二次数据
import pandas as pd
import numpy as np
import csv
data = pd.DataFrame()
data =pd.DataFrame(pd.read_csv('D:/996/grtd.csv',encoding="gbk"))
y = np.array(data['a69'])
x1 = np.array(data['H66'])
import scipy.stats as stats
r1 = stats.pearsonr(x1,y)[0]
import pandas.tseries
import statsmodels.api as sm
import pandas as pd
import numpy as np
vars = ['a69','H66']
df = data[vars]
from patsy import dmatrices
y,X = dmatrices('a69~H66',data = df,
return_type = 'dataframe')
model = sm.OLS(y,X)
result = model.fit()
print(result.summary())
#第三次数据
import pandas as pd
import numpy as np
import csv
data = pd.DataFrame()
data =pd.DataFrame(pd.read_csv('D:/996/cgss2015.csv',encoding="gbk"))
y = np.array(data['a69'])
x1 = np.array(data['a62'])
import scipy.stats as stats
r1 = stats.pearsonr(x1,y)[0]
import pandas.tseries
import statsmodels.api as sm
import pandas as pd
import numpy as np
vars = ['a69','a62']
df = data[vars]
from patsy import dmatrices
y,X = dmatrices('a69~a62',data = df,
return_type = 'dataframe')
model = sm.OLS(y,X)
result = model.fit()
print(result.summary())
#第四次数据
import pandas as pd
import numpy as np
import csv
data = pd.DataFrame()
data =pd.DataFrame(pd.read_csv('D:/996/cgss2015.csv',encoding="gbk"))
y = np.array(data['a69'])
x5 = np.array(data['a301'])
import scipy.stats as stats
r5 = stats.pearsonr(x5,y)[0]
import pandas.tseries
import statsmodels.api as sm
import pandas as pd
import numpy as np
vars = ['a69','a301']
df = data[vars]
from patsy import dmatrices
y,X = dmatrices('a69~a301',data = df,return_type = 'dataframe')
model = sm.OLS(y,X)
result = model.fit()
print(result.summary())




 上一篇
上一篇 
